منشئ بيانات الكلام: أداة إنشاء مجموعات بيانات TTS و STT
نظرة عامة
منشئ بيانات الكلام هو تطبيق ويب قوي ومفتوح المصدر مصمم لتبسيط إنشاء مجموعات بيانات كلام احترافية لتدريب نماذج تحويل النص إلى كلام (TTS) والكلام إلى نص (STT). يعمل بالكامل في المتصفح دون معالجة من جانب الخادم، مما يضمن خصوصية البيانات.
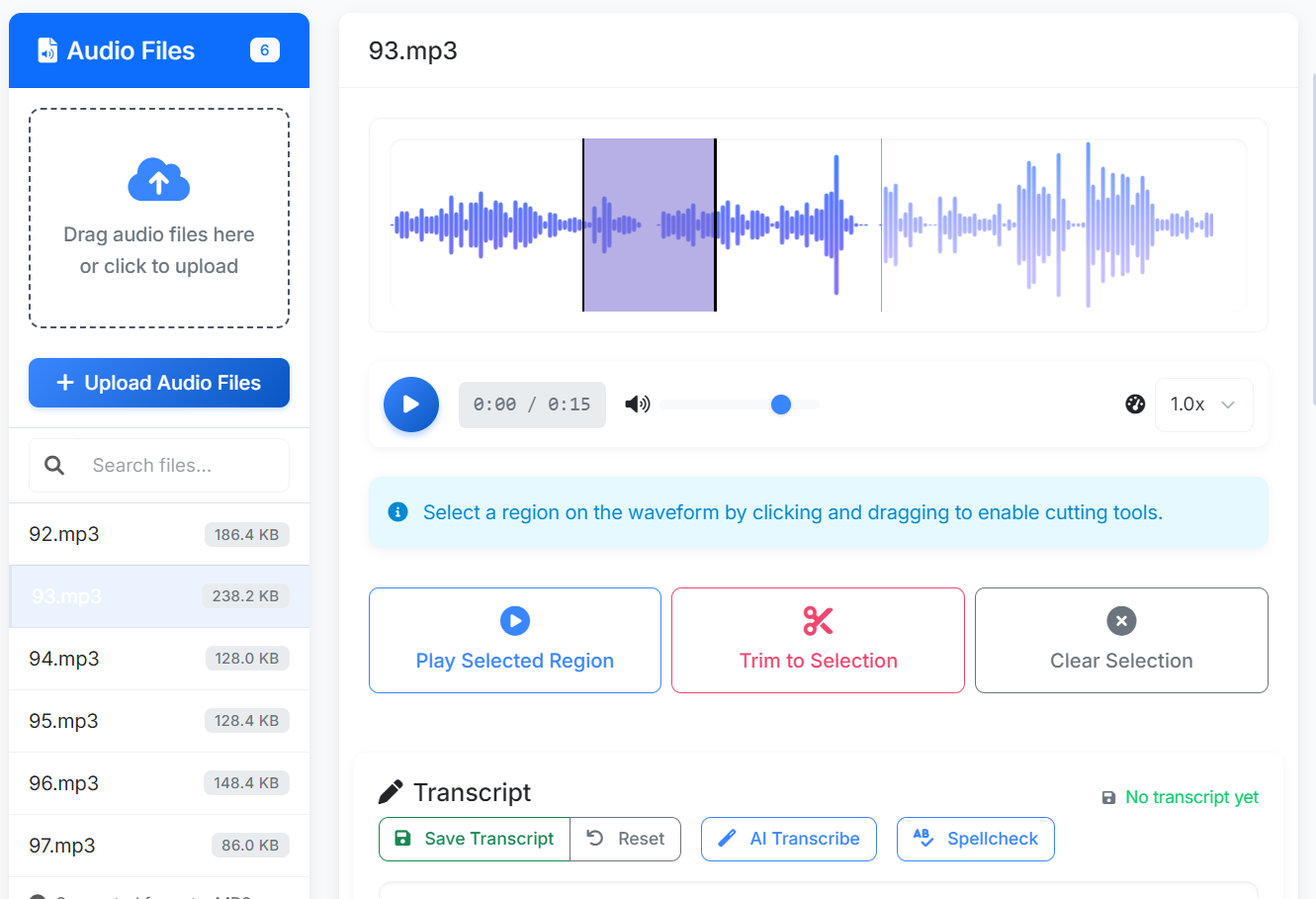
الواجهة الرئيسية (الوضع الفاتح) تُظهر أدوات شكل الموجة والنسخ.
الواجهة الرئيسية (الوضع الداكن). تتميز الأداة بالنسخ المدعوم بالذكاء الاصطناعي (دمج Google Gemini و OpenAI)، والتصور الدقيق للصوت باستخدام WaveSurfer.js، والتطبيع التلقائي للنص. يمكن للمستخدمين تصدير مجموعات البيانات بتنسيقات شائعة مثل LJSpeech و CSV و JSON.
الأهداف
- إنشاء أداة تركز على الخصوصية وتعمل من جانب العميل لإنشاء مجموعات بيانات الكلام.
- دمج خدمات الذكاء الاصطناعي (Google Gemini, OpenAI) لتسريع عملية النسخ.
- توفير تصور دقيق للصوت واختيار المنطقة.
- دعم تنسيقات التصدير القياسية في الصناعة مثل LJSpeech.
المميزات الرئيسية
النسخ المدعوم بالذكاء الاصطناعي
نسخ الصوت تلقائيًا باستخدام نماذج Google Gemini أو OpenAI Whisper.
تصور الصوت
تصور أشكال الموجات الصوتية مع اختيار المنطقة لتحديد الطوابع الزمنية بدقة.
تطبيع النص
تطبيع النص تلقائيًا (الأرقام إلى كلمات، الأحرف الخاصة) لتدريب TTS.
تنسيقات تصدير متعددة
تصدير البيانات إلى تنسيقات LJSpeech و CSV و JSON و TXT.
دعم وضع عدم الاتصال (PWA)
قابل للتثبيت كتطبيق ويب تقدمي (PWA) يعمل دون اتصال بالإنترنت.
التحديات والحلول
التعامل مع ملفات الصوت ومجموعات البيانات الكبيرة بالكامل في المتصفح.
تم استخدام IndexedDB للتخزين الفعال من جانب العميل و JSZip لإنشاء ملفات تصدير كبيرة دون تعطيل المتصفح.
تصور البيانات الصوتية بدقة للتقسيم الدقيق.
تم تطبيق WaveSurfer.js لعرض أشكال موجية مفصلة والسماح بالتحكم الدقيق في المنطقة.